
作用:跨进程资源竞争管理
单master(包括twemproxy分片)
适用范围:
可以容忍master宕机后多个竞争者获取锁。
实现:
# KEYS[1] - lock name
# ARGV[1] - token
# ARGV[2] - timeout in milliseconds
# return 1 if lock was acquired, otherwise 0
LUA_ACQUIRE_SCRIPT = """
if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then
if ARGV[2] ~= '' then
redis.call('pexpire', KEYS[1], ARGV[2])
end
return 1
end
return 0
"""
# KEYS[1] - lock name
# ARGS[1] - token
# return 1 if the lock was released, otherwise 0
LUA_RELEASE_SCRIPT = """
local token = redis.call('get', KEYS[1])
if not token or token ~= ARGV[1] then
return 0
end
redis.call('del', KEYS[1])
return 1
"""
# KEYS[1] - lock name
# ARGS[1] - token
# ARGS[2] - additional milliseconds
# return 1 if the locks time was extended, otherwise 0
LUA_EXTEND_SCRIPT = """
local token = redis.call('get', KEYS[1])
if not token or token ~= ARGV[1] then
return 0
end
local expiration = redis.call('pttl', KEYS[1])
if not expiration then
expiration = 0
end
if expiration < 0 then
return 0
end
redis.call('pexpire', KEYS[1], expiration + ARGV[2])
return 1
"""
注意事项:
- 每个锁都需要设置超时时间,并且精确到毫秒
- 建议使用lua脚本控制锁申请、释放,lua脚本原子执行(也可以使用事务,不过twemproxy等集群方案不支持事务)
- 超时时间一定要高于临界区执行时间,否则会破坏锁的互斥性(无法完全避免)
- token用于标识锁拥有者的身份,避免释放了其他竞争者的锁
- token建议使用threadlocal存储,避免释放了其他竞争者的锁
场景分析:
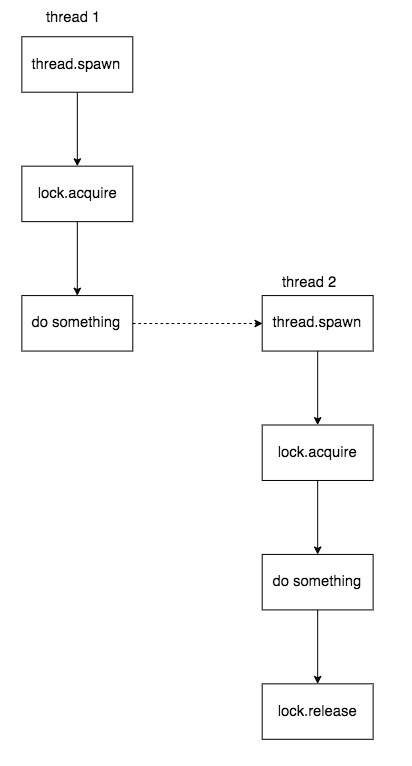
1,锁过期,但是当前的拥有者仍然还在执行任务,然后另外的竞争者获取到了锁,互斥性被破坏
只能尽量避免,不能彻底规避:
- 只锁定必要的临界区
- 锁超时时间高于临界区执行时间
2,多线程模型,未使用threadlocal存储token,释放了错误的锁
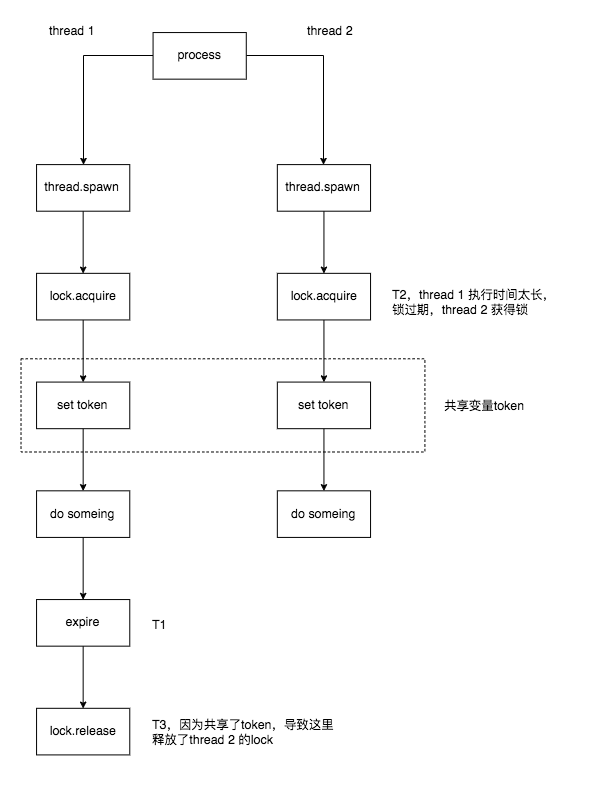
3,多线程锁传递,不应当使用threadlocal
适用于一个行为需要多个线程协同完成的场景。
在分布式版本的算法里我们假设我们有N个Redis master节点,这些节点都是完全独立的,在我们的例子里面我们把N设成5,这个数字是一个相对比较合理的数值,因此我们需要在不同的计算机或者虚拟机上运行5个master节点来保证他们大多数情况下都不会同时宕机。一个客户端需要做如下操作来获取锁:
- 获取当前时间(单位是毫秒)。
- 轮流用相同的key和随机值在N个节点上请求锁,在这一步里,客户端在每个master上请求锁时,会有一个和总的锁释放时间相比小的多的超时时间。比如如果锁自动释放时间是10秒钟,那每个节点锁请求的超时时间可能是5-50毫秒的范围,这个可以防止一个客户端在某个宕掉的master节点上阻塞过长时间,如果一个master节点不可用了,我们应该尽快尝试下一个master节点。
- 客户端计算第二步中获取锁所花的时间,只有当客户端在大多数master节点上成功获取了锁(在这里是3个),而且总共消耗的时间不超过锁释放时间,这个锁就认为是获取成功了。
- 如果锁获取成功了,那现在锁自动释放时间就是最初的锁释放时间减去之前获取锁所消耗的时间。
- 如果锁获取失败了,不管是因为获取成功的锁不超过一半(N/2+1)还是因为总消耗时间超过了锁释放时间,客户端都会到每个master节点上释放锁,即便是那些他认为没有获取成功的锁。
def lock(self, resource, ttl):
retry = 0
val = self.get_unique_id()
# Add 2 milliseconds to the drift to account for Redis expires
# precision, which is 1 millisecond, plus 1 millisecond min
# drift for small TTLs.
drift = int(ttl * self.clock_drift_factor) + 2
redis_errors = list()
while retry < self.retry_count:
n = 0
start_time = int(time.time() * 1000)
del redis_errors[:]
for server in self.servers:
try:
if self.lock_instance(server, resource, val, ttl):
n += 1
except RedisError as e:
redis_errors.append(e)
elapsed_time = int(time.time() * 1000) - start_time
validity = int(ttl - elapsed_time - drift)
if validity > 0 and n >= self.quorum:
if redis_errors:
raise MultipleRedlockException(redis_errors)
return Lock(validity, resource, val)
else:
for server in self.servers:
try:
self.unlock_instance(server, resource, val)
except:
pass
retry += 1
time.sleep(self.retry_delay)
return False
注意事项:
- 不同redis实例存在时间偏差(时间不同,时间跃迁速度不同等,偏差一般很小),时间偏差会导致时间慢的redis上的key先过期,为了减小影响,redlock添加了clock drift变量(clock_drift_factor = 0.01;drift = int(ttl * self.clock_drift_factor) + 2),计算锁可用时间时会减去clock drift
- MIN_VALIDITY=TTL-(T2-T1)-CLOCK_DRIFT,TTL是锁超时时间、(T2-T1)是最晚获取到的锁的耗时,CLOCK_DRIFT是不同进程间时钟差异
场景分析:
1,redis崩溃,锁丢失,互斥性被破坏
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- 客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- 节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,可以通过延迟重启解决。即一个节点崩溃后,等待一段时间再重启,这段时间应该大于锁的有效时间,这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
2,锁超时释放,互斥性被破坏
具有自动释放锁的分布式锁都没办解决这个问题。